接着上篇 Nodejs爬虫–抓取豆瓣电影网页数据(上)
本篇主要描述将上次抓取的数据存入mongodb数据库
前提:百度或谷歌mongodb的安装教程,安装本地并成功运行
推荐一款mongodb数据库可视化管理工具:Robomongo。可以加群264591039获取安装包或自行寻找资源
首先用npm安装第三方数据库操作包:mongoose.
关于mongoose详情请查看官方文档
1
| npm install --save-dev mongoose
|
引入mongoose包开始对mongodb进行管理
当前目录下新建一个mongo.js文件方便管理,在该文件中引入相关包:
1 2
| let mongoose = require('mongoose'), assert = require('assert');
|
获取表构造器Schema并映射mongodb相应的collection
1 2 3 4 5 6 7 8 9 10 11 12 13
| let Schema = mongoose.Schema; let filmSchema = new Schema({ //自定义相应的表数据字段 title: String, type: String, directories: String, scriptwriter: String, actors: String }); //映射collection并生成model对象用于管理数据表的增删改查 //默认是映射到名为films的collection //若自定义表明则:let filmSchema = new Schema({..}, { collection: 'data' }); 'data'即为自定义名称 let Film = mongoose.model('Film', filmSchema);
|
连接mongodb数据库并exports Film对象
1 2 3 4 5 6 7 8 9
| let db = mongoose.connect('mongodb://127.0.0.1:27017/spider'); db.connection.on('error', (err) => { console.log(`数据库连接失败:${err}`); }); db.connection.on('open', () => { console.log('数据库连接成功'); }); module.exports = {Film: Film};
|
在spider.js中引入Film对象并添加入库操作代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
| let mongo = require('./mongo'); //在请求网页的end函数中添加入库操作 xxxx.end((err, res) => { var $ = cheerio.load(res.text); //用cheerio获取整个页面DOM对象 var _data = {title:'', type: '', directories: '', scriptwriter: '', actors: ''}; _data.title = $('#content h1 span').text(); _data.directories = $('#info .attrs').eq(0).text(); _data.scriptwriter = $('#info .attrs').eq(1).text(); _data.actors = $('#info .attrs').eq(2).text(); $('span[property="v:genre"]').each(function (index) { _data.type += ($(this).text() + (index == $('span[property="v:genre"]').length - 1 ? '' : '、')); }); console.log(_data); mongo.Film.create(_data, (err, doc) => { assert.equal(err, null); console.log(doc); }); });
|
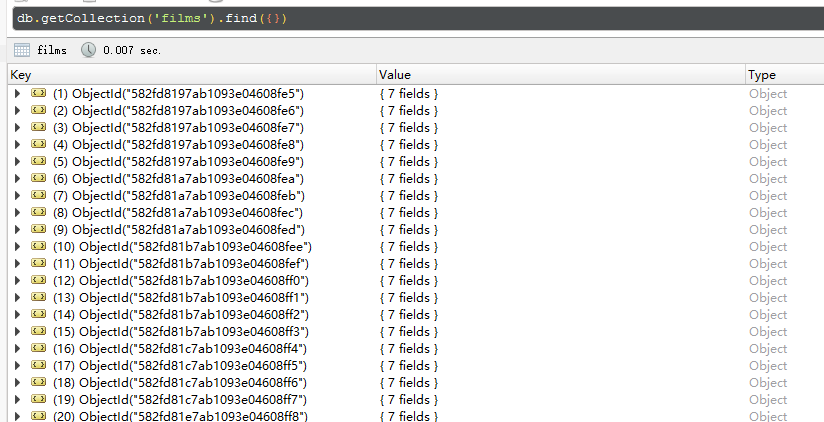
运行spider.js,并查看数据库中的数据
1 2
| node spider.js //用上述提到的可视化工具查看数据库是否成功有数据入库
|